NVIDIA H100 – oto najpotężniejszy akcelerator graficzny na rynku. Wielka zapowiedź architektury Hopper

0
1
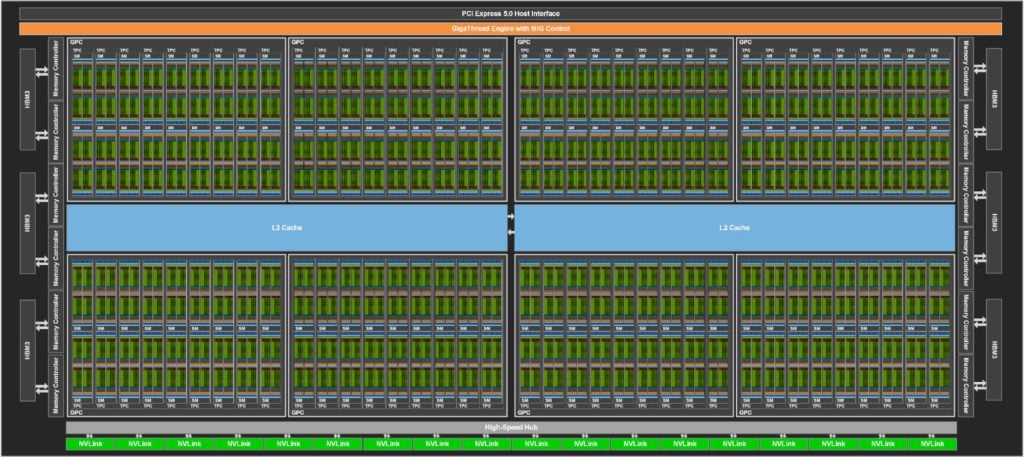
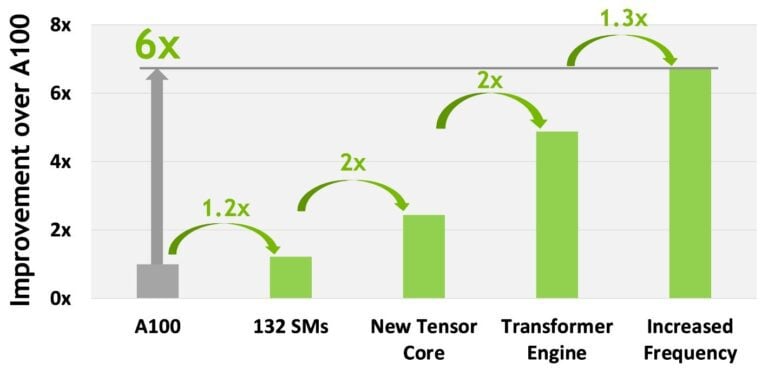
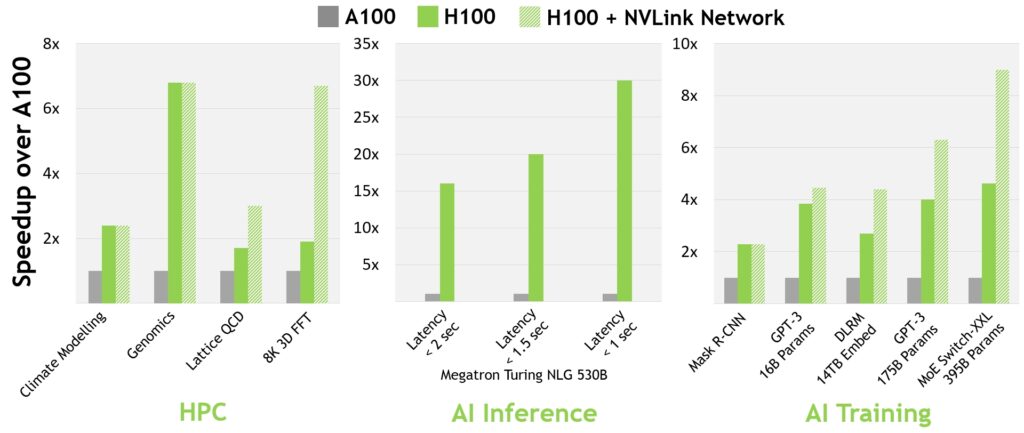
NVIDIA zapowiedziała na Game Developers Conference (GTC 2022) najpotężniejszy akcelerator graficzny H100. Jego prezentacja pokryła się z wielką zapowiedzią architektury Hopper, na której opiera się najnowszy układ przeznaczony do zaawansowanych obliczeń. Poprzedni akcelerator NVIDIA, Ampere A100, wygląda przy nim blado. Poznaj szczegóły na temat architektury Hopper i akceleratorze graficznym H100.








 – premiera, specyfikacja i wydajność")

